from series, words and their mappings.
journey of embeddings
At the first post of this series, Words and Their Mappings, I briefly talked about words, their notational nature, latent space and LLMs.
I decided that embeddings are the central concept for understanding the power of LLMs, and deserve dedicated blog posts: one from beginnings to BERT and GPT, and one for LLM era.
So, let's talk about the journey of embeddings and latent space!
Beginnings
As known, machine learning models perform mathematical operations. But, not all data is numerical. In order to enable machine learning models to perform mathematical operations on non-numerical data (such as text), we should somehow represent the data numerically.
Categorical Variables
At first, we used basic methods for assigning numbers to the categorical variables or words. The first thing come to mind naturally is assigning numbers arbitrarily to each word/category. For example, if our vocabulary simply consists of words car, motorcycle, bicycle, ship and plane, we can assign 1, 2, 3, 4, 5 to each of them, respectively. Or say we choose to do this randomly, 10, 50, 5, 1, 1000.
Technically, a machine learning algorithm would attempt to learn a model on this data. But, there will be a problem: a false pattern will be learnt according to the order and relationships to the numbers we assigned. Maybe it would return a result of "bicycle" for a pattern could both match "car" and "plane".
In order to mitigate this, another approach is used in classical machine learning models: one-hot encoding. In this approach, words are simply defined as a fixed size vector, where only one element is set to 1, others to 0. The element set to 1 corresponds to the column representing the word itself. By doing that, we get rid of the false representations of relationships between the words.

While simple, one-hot encoding had significant limitations:
- These one-hot encoded vectors are orthogonal. Any two vectors have cosine similarity of zero, for example. They bear no meaningful relationships to each other. While we are removing all false similarities, we actually removed all kinds of similarities. Each word is an isolated atom.
So, it cannot capture any semantic relationships between words. For instance, even though they share similar meanings as land vehicles, "car" and "motorcycle" would be as unrelated as "car" and "cloud". Models do not learn meanings of words in that case, they learn words as categorical variables.
- Also, words are represented as sparse vectors, and vector lengths should be as much as the count of words in the dictionary. For a dictionary of a million words, that would mean a million columns to be added to the data. This severely limits the learning ability of machine learning models, because of the "curse of dimensionality".
Count Based Methods on Documents
Natural Language Processing is not about digitizing isolated words, of course. It's about understanding and analyzing text. We want to process documents, paragraphs, sentences or phrases.
To go beyond the limitations of one-hot encoding, statistical, count-based methods, such as bag-of-words (BoW) and term frequency-inverse document frequency (TF-IDF) are developed. This family of methods allowed pieces of texts to be represented according to the words they contain, and provided a means to gain insight about them.
So again, we are constructing vectors, but in a different way:
Bag-of-Words (BoW) is a simple technique that represents documents by counting the occurrences of each word within these documents. Each unique word in the vocabulary becomes a feature (or column), and the document is simply represented as a vector of these word counts. By doing that, we gain the ability to compare different documents/pieces of text according to their content in terms of words.
Term Frequency-Inverse Document Frequency (TF-IDF), which is an improved version of BoW, weights frequencies of each word within a document relative to its frequency across all documents. Words that appear frequently in one document but are rare across others receive higher weights, highlighting their importance to that document.
TF-IDF provides a more refined representation than BoW by distinguishing common terms from unique, document-specific terms. This allows many powerful applications such as lexical search alongside machine learning.
In both methods, at least the document vectors are no longer completely orthogonal now, as documents that share common words will have overlapping non-zero values, representing a shared vocabulary and thematic content.
However, while BoW and TF-IDF provide foundational ways to represent text, they have limitations:
- Semantic relationships between words are non-existent. Words are still treated as atoms.
- Sentences change meaning according to the word order. Information about word order is simply non-existent.
- Vectors are still sparse. They are as large as the count of unique words in a piece of text.
One Step Further
In order to address these issues, latent structure within the data was began to be explored. For example, in the methods of Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA).
As mentioned before, methods like BoW and TF-IDF generate a sparse term-document matrix. Introduced by Deerwester et al. (1990), LSA uses singular value decomposition (SVD) on the term-document matrix to reduce dimensionality. This reduction not only provides ease of computation by reducing the dimensionality, but also uncovers patterns of co-occurrence that reveal hidden relationships between words and concepts, clustering similar terms in a semantic space.
Proposed by Blei, Ng, and Jordan (2003), LDA adopts a probabilistic approach to uncovering latent structure. Unlike LSA, which relies on matrix decomposition, LDA models documents as a mixture of topics, where each topic is a probability distribution over words. This allows it to assign weights to different topics for a document.
For instance, in a document about "space exploration," LDA might assign 70% to a "space" topic (with words like "rocket" and "NASA") and 30% to a "technology" topic (with words like "robotics" and "AI"). By modeling documents in this way, LDA captures thematic structures that go beyond mere word counts.
As computing power improved, researchers began exploring neural networks to enhance text representations. With these models, the idea of learning from context started to gain popularity.
By Bengio et al. (2003), Neural Probabilistic Language Models (NPLMs) used neural networks to predict the likelihood of the next word in a sequence. Unlike BoW or TF-IDF, NPLMs captured the sequential dependencies between words. For instance, in the phrase "The cat sat on the," the model could predict "mat" by learning patterns in word order and syntax.
Unified Architecture for NLP, milestone paper by Collobert and Weston (2008), proposed a shared embedding space that could be used across multiple NLP tasks, such as part-of-speech tagging and named entity recognition. The key innovation was the introduction of pre-trained embeddings—word representations learned from large corpora that could generalize to multiple tasks without requiring task-specific models.
Collobert and Weston demonstrated the power of neural embeddings to capture semantic relationships across tasks. For example, words like "apple" (the fruit) and "orange" (another fruit) would cluster together, distinct from "Apple" (the company). This concept of pre-training would later inspire transformative models we are using today.
While revolutionary, neural network based models needed extensive use of computational power. So, they had to wait for their time a little bit more.
Word2Vec, Doc2Vec, GloVe
Years passed, and ability to access computational power is improved. Also, large datasets which are crucial for training machine learning became accesible. So, machine learning began to be revisited as a method for various stages of NLP.
This renewed exploration led to the development of Word2Vec, by Mikolov et al. (2013).
In Word2Vec, co-occurrence is again introduced as a key idea for natural language processing. Instead of treating each word as an isolated entity (as in Bag-of-Words or TF-IDF), Word2Vec recognized that words appearing in similar contexts are likely to share related meanings.
This concept, rooted in distributional semantics, is elegantly summarized by linguist J.R. Firth's famous quote from the 1950s:
You shall know a word by the company it keeps.
Word2Vec uses this idea by looking at which words appear frequently near each other in large text corpora. Words that share similar company, contextual neighbors, are mapped to similar vector representations in a continuous vector space, by this machine learning model.
There are two main approaches Word2Vec uses to leverage co-occurrence:
- Skip-Gram Model: Predicts the context (neighboring words) for each target word. For example, given the word "dog," the model learns to predict words like "barks," "tail," "pet," or "animal."
- Continuous Bag of Words (CBOW): Predicts the target word based on its surrounding context words. For example, given the context words "tail," "barks," "pet," and "animal," the model would learn to predict "dog."

This innovation represents a paradigm shift: instead of sparse, high-dimensional vectors, Word2Vec produces dense, lower-dimensional embeddings that captures rich semantic relationships. Besides capturing semantic relationships and even allow for interesting vector arithmetic like:
king - man + woman ≈ queen
Unlike one-hot encoding, where each vector is orthogonal and lacks any relational structure, Word2Vec maps words into a lower-dimensional space where proximity in this space reflects similarity in meaning or usage. Words with similar contexts, like "car" and "bicycle," are positioned close together, while unrelated words are placed farther apart.
The space that contains these embedding vector is called latent space, because it reveals underlying, latent, hidden patterns derived from co-occurrence data rather than directly observed features. Each dimension in this latent space encodes abstract, latent characteristics of words, such as gender, pluralization, or thematic similarity, or any other thing we do not normally think about, without these features being explicitly labeled or defined. Through training, Word2Vec captures these complex relationships, making the latent space a nuanced, multi-dimensional representation of semantic knowledge.
Word2Vec revolutionized how words are represented in vector space, but it focused only on individual words, ignoring the broader structure and meaning of documents or sentences. This limitation inspired the development of Doc2Vec (Le and Mikolov, 2014), which extended Word2Vec to generate embeddings for entire documents (just as extension from one-hot vectors to the documents vectors in BoW and TF-IDF!)
By introducing a document vector, Doc2Vec enabled models to represent the unique context of a document alongside word vectors. This innovation was particularly useful for tasks like document classification and similarity, paving the way for further exploration of embeddings beyond single-word representations.
While Word2Vec relies on local co-occurrence within a sliding context window to learn embeddings, GloVe (Pennington et al., 2014) takes a more global approach. GloVe is trained on a global co-occurrence matrix that captures how frequently words appear together across the entire corpus, rather than just within a narrow window. This approach allows GloVe to encode richer semantic and thematic relationships between words, leveraging the entire corpus for context.
Certainly Word2Vec, GloVe and Doc2Vec were breakthroughs in creating vector representations of words or paragraphs based on their semantic relationships. But they had several notable limitations we needed to solve to reach today's capabilities:
- They produce static embeddings, meaning each word or document has a single, fixed representation regardless of context. For example, in word2vec, this approach fails to capture the nuances of polysemous words (e.g., "plane" as a vehicle vs. "plane" as a surface), limiting the model’s understanding of context.
- Additionally, Word2Vec does not account for word order; it only considers co-occurrence within a limited context window, which means sentences like "dog bites man" and "man bites dog" would produce similar embeddings despite their very different meanings.
- The models also requires fixed vocabulary and struggles with out-of-vocabulary (OOV) words, as they cannot dynamically create embeddings for new terms. Also, they struggle in morphologically rich languages, where prefixes and suffixes play a critical role in meaning.
- Finally, as shallow models, they are effective for basic semantic relationships but struggle to capture deeper linguistic structures or long-range dependencies critical for complex tasks.
More Steps Further
fastText

One of the first significant advancements after Word2Vec was fastText, introduced by Facebook AI Research (FAIR).
Instead of representing each word as a single atomic unit, fastText breaks down words into smaller subword components called character n-grams, capturing morphological structure within words.
This approach allows fastText to handle some of the out-of-vocabulary (OOV) words effectively, as it can generate embeddings for unseen words by combining the embeddings of their subword components.
For example, I just coined a word now: MoEOps. It is like MLOps, managing the machine learning life cycle, but for mixture-of-experts models. Normally, a word2vec model that is trained just before I coined the term would fail to recognize it. But, a recently trained fastText model would be able to, since it learnt subwords "MoE" and "Ops".
Additionally, fastText performs better with morphologically rich languages, since they frequently use prefixes and suffixes as notations for meanings.
However, while fastText improved the handling of out-of-vocabulary words and morphological variations, it still shared some fundamental limitations with Word2Vec.
Specifically,
- fastText embeddings are still static. Each word still has a single, fixed representation regardless of context. So, it couldn’t differentiate between different meanings of polysemous words based on their usage either. "Plane as a vehicle" and "plane as a surface" still could not be distinguished.
- fastText didn't capture word order or syntactic relationships between words. That limits its understanding to simple co-occurrence patterns. It is still a word (single word) embedding model. "Man eats dog" and "dog eats man" still have the same meanings.
- fastText also struggled with long range dependencies.
Recurrent Neural Networks (RNNs)
In the 1990s, following the foundational paper "Finding Structure in Time" by Jeffrey Elman (1990), Recurrent Neural Networks (RNNs) emerged as a powerful method for handling sequential data. These networks enabled machine learning models to capture temporal dependencies, making them suitable for tasks like time series analysis, sequence prediction, and language modeling. The field saw significant advancements with the introduction of the Long Short-Term Memory (LSTM) architecture by Hochreiter and Schmidhuber in 1997, which addressed challenges like the vanishing gradient problem. LSTMs revolutionized tasks such as language modeling, speech recognition, and machine translation, setting a foundation for modern neural sequence models.
Before embeddings like Word2Vec, RNNs and LSTMs typically worked with one-hot encoded vectors or count-based features (e.g., BoW or TF-IDF). Of course this was inefficient because of dimensionality (sparse vectors) and context independence (words as atoms).
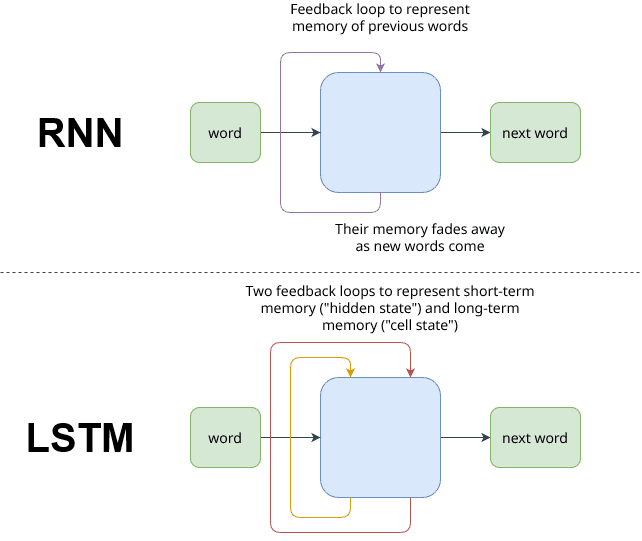
When embeddings are introduced, they improved RNNs by providing dimensionality reduction, semantic similarity, and emerged inherent knowledge of language.
While dimensionality reduction make models able to process large amounts of data, semantic similarity and emerged inherent knowledge of language provided a means for building upon them for specific tasks.
However, there were still some problems with RNNs:
- RNNs and LSTMs relied on static embeddings, such as Word2Vec or GloVe, which assigned a single, fixed representation to each word regardless of its context. "Plane as a vehicle" and "plane as a surface" are still indistinguishable.
- RNNs, and even to some extent LSTMs, struggle with long-range dependencies in sequences. The gradients can become extremely small (vanishing) or excessively large (exploding) during backpropagation, making it hard to learn from earlier parts of a sequence. They struggle to maintain a broad understanding of the entire context due to their architecture. Capturing global dependencies over very long texts is challenging.
- RNNs process sequences step by step, making them inherently sequential. This limits parallelization during training and inference, leading to inefficiency with large datasets and long sequences.
- If input and output sequences (for example, sentences) have different lengths, RNNs and LSTMs struggle to perform properly.
These shortcomings highlighted the need for more sophisticated approaches.
Encoders, Decoders and Attention
In 2014, the encoder-decoder architecture was introduced, by Sutskever et al. in their 2014 paper "Sequence to Sequence Learning with Neural Networks." This framework was designed to transform one sequence into another, as required in tasks like machine translation.
The encoder-decoder architecture works by encoding the input sequence into a fixed-length vector that represents the entire sequence. This vector is then used by the decoder to generate the target sequence. We can think of this fixed-length vector as the internal notation of the models for meaning of the sequence/sentence.
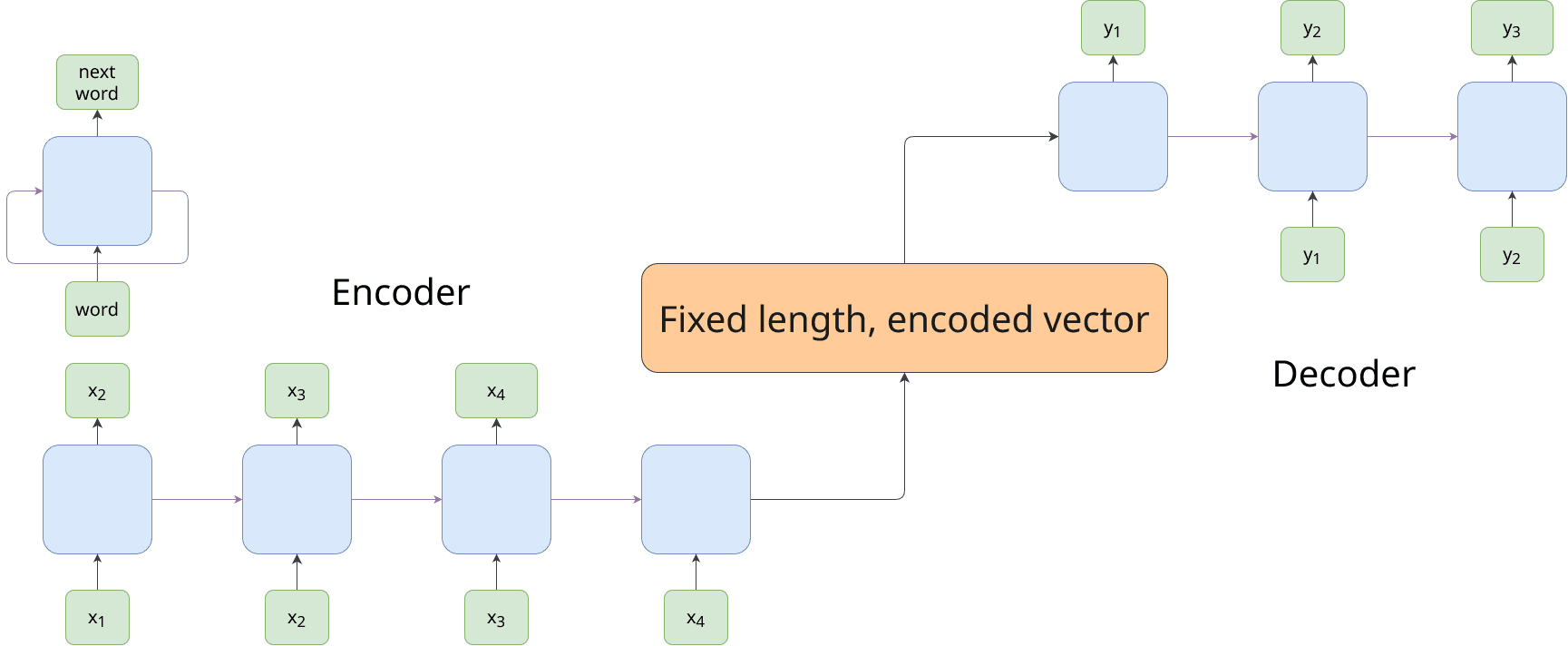
While this approach improved the ability to handle sequence-to-sequence tasks, it still struggled with long-range dependencies, as the fixed-length vector had to compress all information from the input sequence. This limitation often led to a loss of critical context for longer sentences.
The next breakthrough came with the introduction of the attention mechanism by Bahdanau et al. in their 2015 paper "Neural Machine Translation by Jointly Learning to Align and Translate." Attention revolutionized the encoder-decoder architecture by allowing the decoder to selectively focus on specific parts of the input sequence at each step of decoding, rather than relying on a single fixed-length vector.
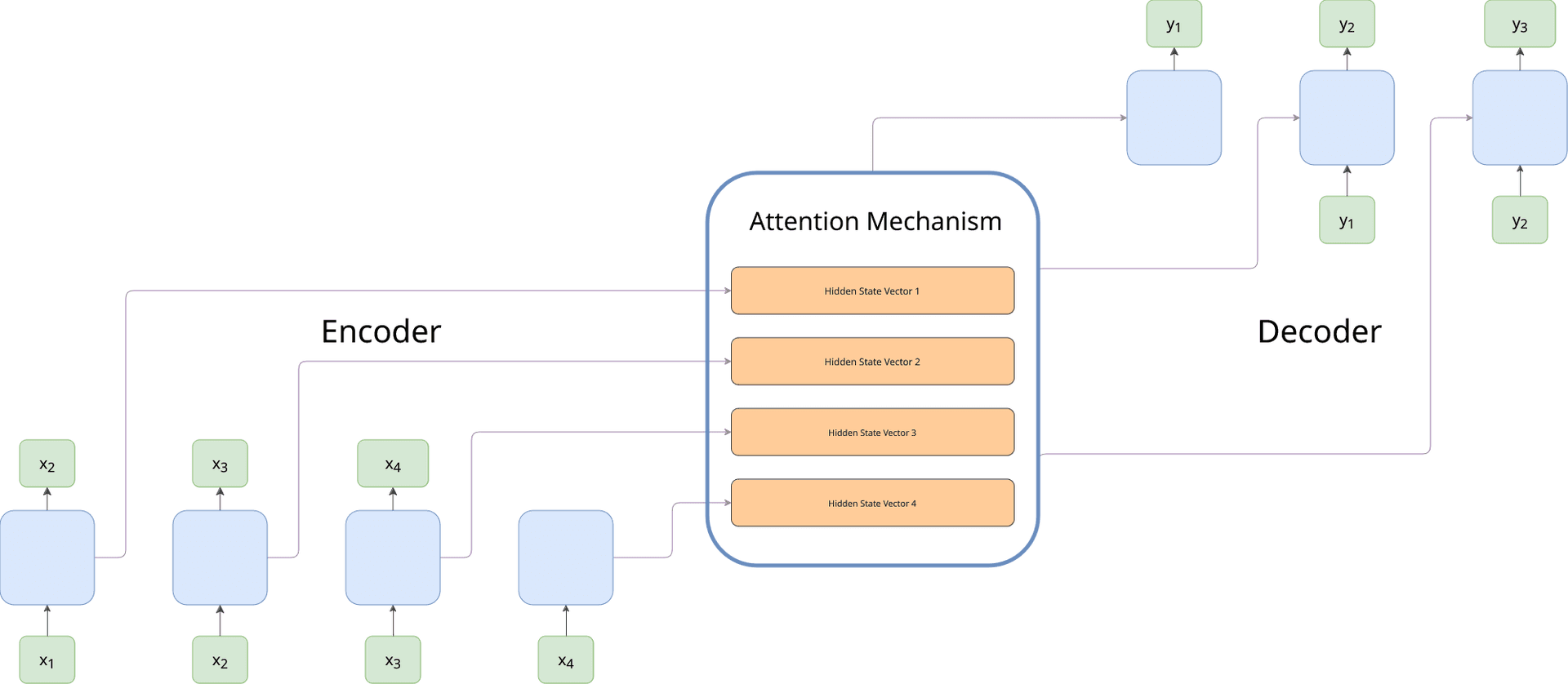
For example, when translating a long sentence, the attention mechanism enables the model to dynamically align and prioritize words or phrases in the input sequence that are most relevant to the current word being generated in the target sequence. This not only improved translation quality but also provided a way to better capture long-range dependencies and syntactic relationships.
By using attention, the model implicitly created contextual representations of words, as their importance was weighted based on surrounding information.
With the success of attention mechanisms in machine translation, researchers quickly recognized their potential for other sequence-to-sequence tasks. Models incorporating attention were applied to:
- Summarization: Allowing models to focus on the most relevant parts of a text when generating a summary.
- Speech Recognition: Enhancing alignment between audio signals and textual representations in models like Listen, Attend, and Spell (Chan et al., 2016).
- Image Captioning: Enabling models to generate captions for images by attending to specific regions of an image (Show, Attend, and Tell, Xu et al., 2015).
These innovations demonstrated that attention mechanisms could be generalized beyond translation, becoming a foundational tool for a variety of NLP and multimodal tasks.
However, traditional attention mechanisms were still dependent on RNNs or LSTMs for sequential processing. While these architectures benefited from the addition of attention, they still suffered from challenges like vanishing gradients and inefficiency in parallelizing computations.
Attention is All You Need
In 2017, paper "Attention is All You Need" by Vaswani et al. introduced a new paradigm in natural language processing: the transformer architecture. This model broke away from the reliance on RNNs and LSTMs entirely, using self-attention as its primary mechanism for understanding sequences.
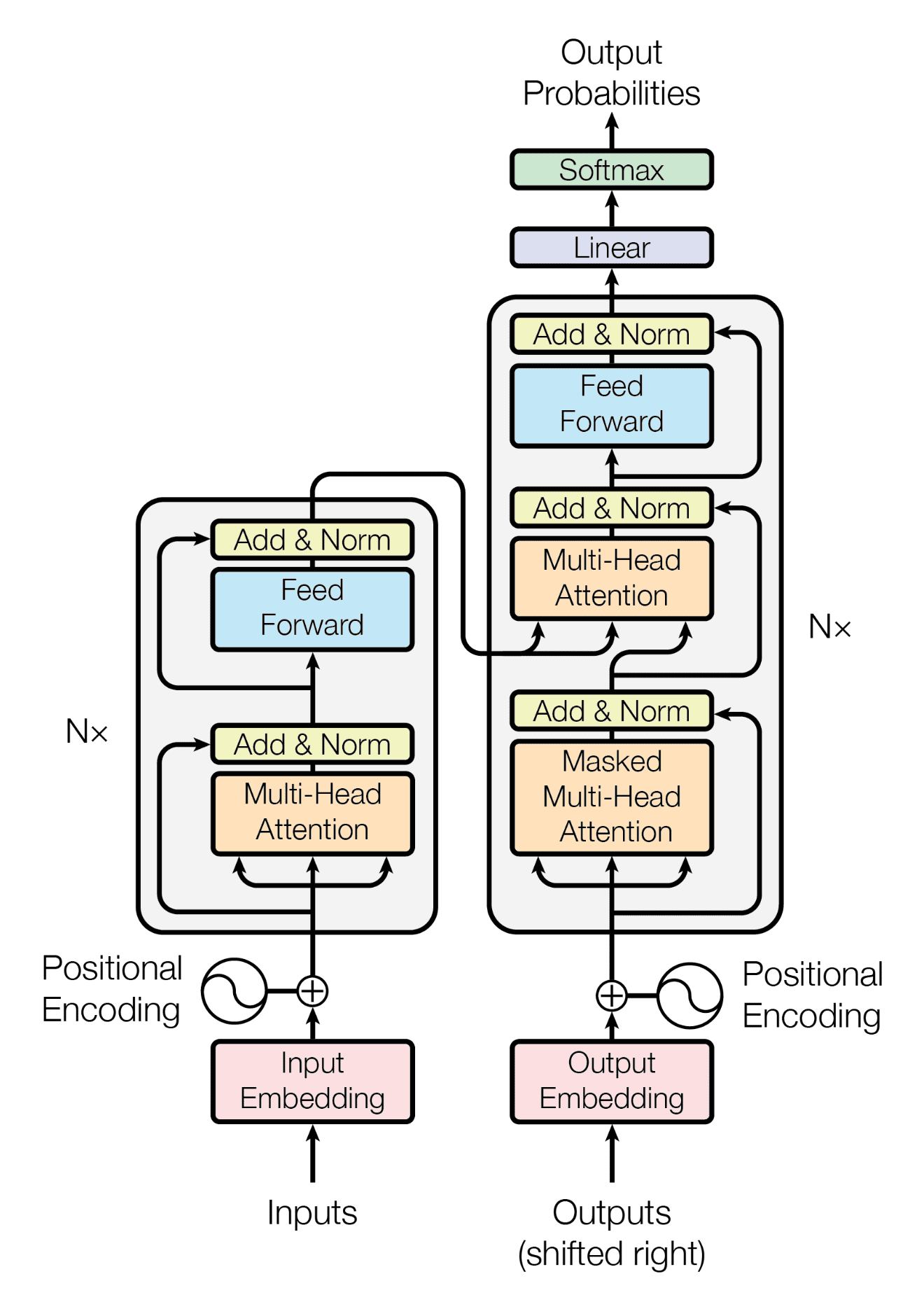
The transformer’s self-attention mechanism enables the model to weigh the relationships between all words in a sequence simultaneously, rather than processing words sequentially.
This provides an ease of parallelization, by using positional encodings. By eliminating the sequential bottleneck of RNNs, transformers not only improved computational efficiency but also scaled effectively to massive datasets and complex tasks. This innovation laid the groundwork for subsequent advancements in NLP.
There was still a problem: embeddings were static. While the transformer architecture introduced self-attention and positional encodings, the embeddings produced by early transformer implementations like those in "Attention is All You Need" were static, meaning that a word's representation did not dynamically change based on its context. "Plane as a vehicle" and "plane as a surface" were still the same.
Around the same time, researchers sought to address this limitation still using recurrent architectures (they were not entirely convinced that attention was all they needed). In 2018, Peters et al. introduced ELMo (Embeddings from Language Models) in their paper "Deep Contextualized Word Representations". Unlike earlier static embeddings, ELMo generated contextual embeddings by combining representations from a bidirectional LSTM language model. This meant that each word's embedding dynamically adjusted based on the entire sentence.
ELMo would assign different embeddings to "plane," reflecting its specific meaning in each context. This breakthrough made ELMo particularly effective for tasks requiring nuanced language understanding, such as question answering and named entity recognition.
However, ELMo still relied on recurrent architectures, which limited its efficiency and scalability. Its bidirectional LSTM structure required sequential processing, making it slower and less parallelizable compared to transformer-based approaches.
Then, a convergence occured, best of two worlds.
Transformers + Contextual Embeddings
The next breakthrough came with BERT (Bidirectional Encoder Representations from Transformers), introduced by Devlin et al. in 2018. BERT combined the power of transformers with the concept of contextual embeddings, eliminating the sequential processing bottleneck while significantly advancing NLP capabilities.
BERT achieved contextual embeddings through its two key innovations:
- Masked Language Modeling (MLM): By randomly masking tokens in the input and predicting them, BERT learned bidirectional relationships in context, allowing embeddings to reflect both left and right context simultaneously.
- Next Sentence Prediction (NSP): This auxiliary task trained BERT to understand sentence-level relationships, further enriching its contextual understanding.
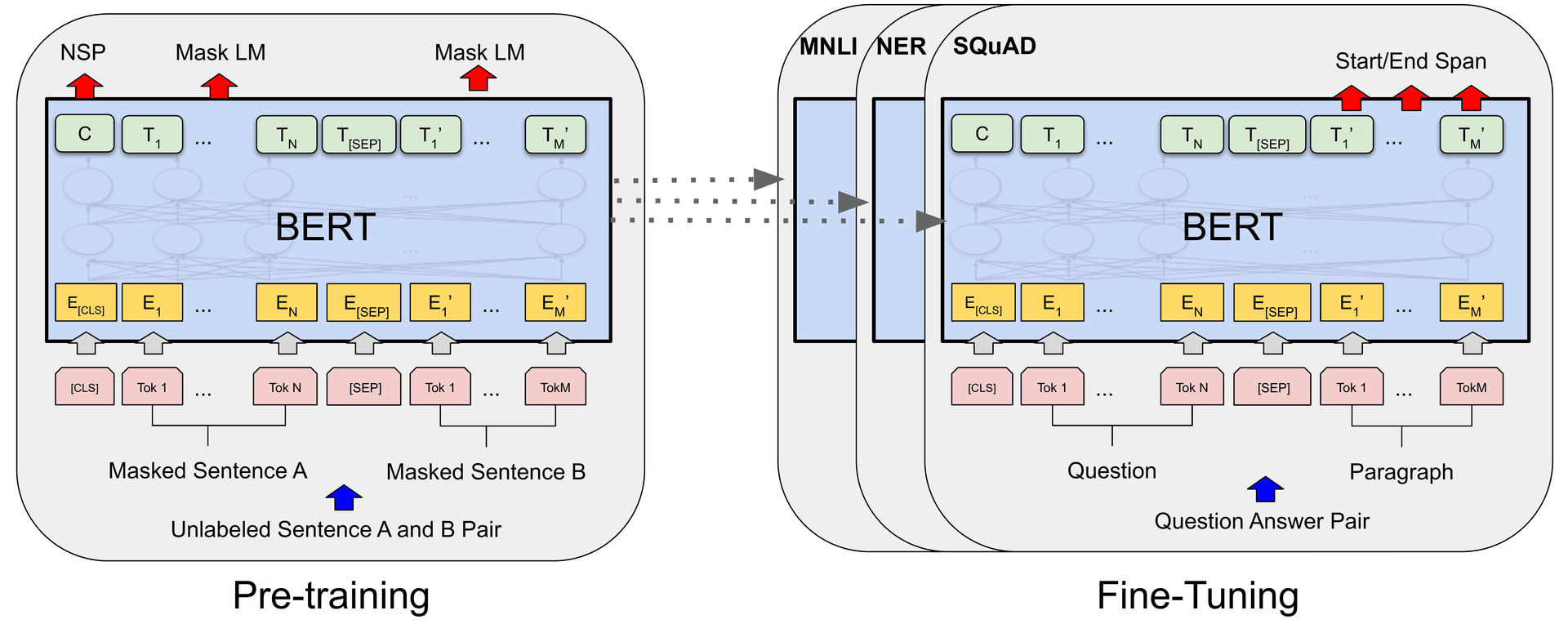
With BERT, contextual embeddings reached new heights, outperforming ELMo and setting a new standard for language models. Its transformer-based architecture enabled unparalleled scalability, making it a foundational model for modern NLP.
Also, using pre-trained models and fine-tuning them for specific (downstream) tasks started become a wider practice among practitioners.
BERT focuses on understanding tasks like classification, named entity recognition, question answering, by considering context from both the left and the right of a token. This bidirectional nature makes it excellent for tasks like sentiment analysis, entity recognition, and question answering. But, it was not suitable for generative tasks like text generation.
Around the same time, in 2018, OpenAI introduced GPT (Generative Pre-trained Transformer), marking a significant leap forward in transformer applications, especially for generative tasks like text completion and creative writing. While BERT excelled at understanding tasks, GPT aimed to unlock the full potential of transformers for language generation.
In contrast to BERT’s bidirectional masking, GPT uses an autoregressive approach, training the model to predict the next word in a sequence based only on the left (previous) context. And GPT’s pre-training objective focuses entirely on next-word prediction, optimizing it for fluency and coherence in generative tasks. This makes it ideal for tasks requiring sequential generation, such as writing coherent essays or crafting natural-sounding dialogue.
The journey of word embeddings and latent space is a testament to the continuous innovation in natural language processing. From the ordinary one-hot encodings to the transformative contextual embeddings of BERT and GPT, we’ve moved from treating words as isolated atoms to understanding them as dynamic representations influenced by their context. These breakthroughs have fundamentally changed how machines process language, enabling models to not only understand but also generate human-like text.
What makes this evolution so groundbreaking is the emergence of latent space—a multi-dimensional representation that captures hidden patterns, relationships, and even abstract concepts about language. Words are no longer arbitrary symbols; they become notations for models to learn mathematical entities connected to each other semantically. Through latent space, machine learning models gain the ability to navigate the intricate web of human language, mapping relationships and uncovering insights that go beyond simple rules or surface-level statistics.
However, this is not the end of the story.
As known, the capabilities of current large language models (LLMs)—their reasoning, creativity, and adaptability—go far beyond BERT and GPT. In the next post, we will look at the LLM era, exploring how post-GPT models like GPT-3, GPT-4, and others build on this foundation to redefine what machines can do with language.
Stay tuned!